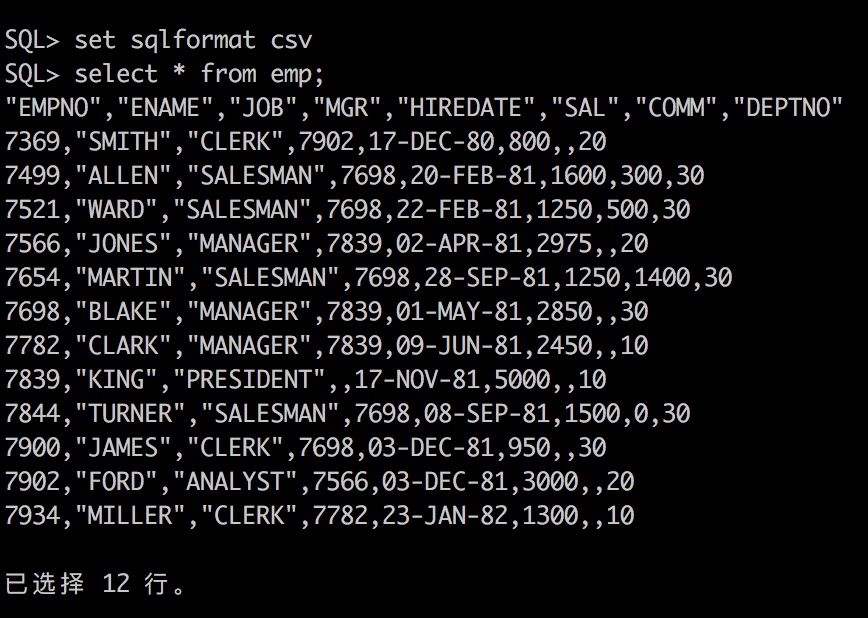
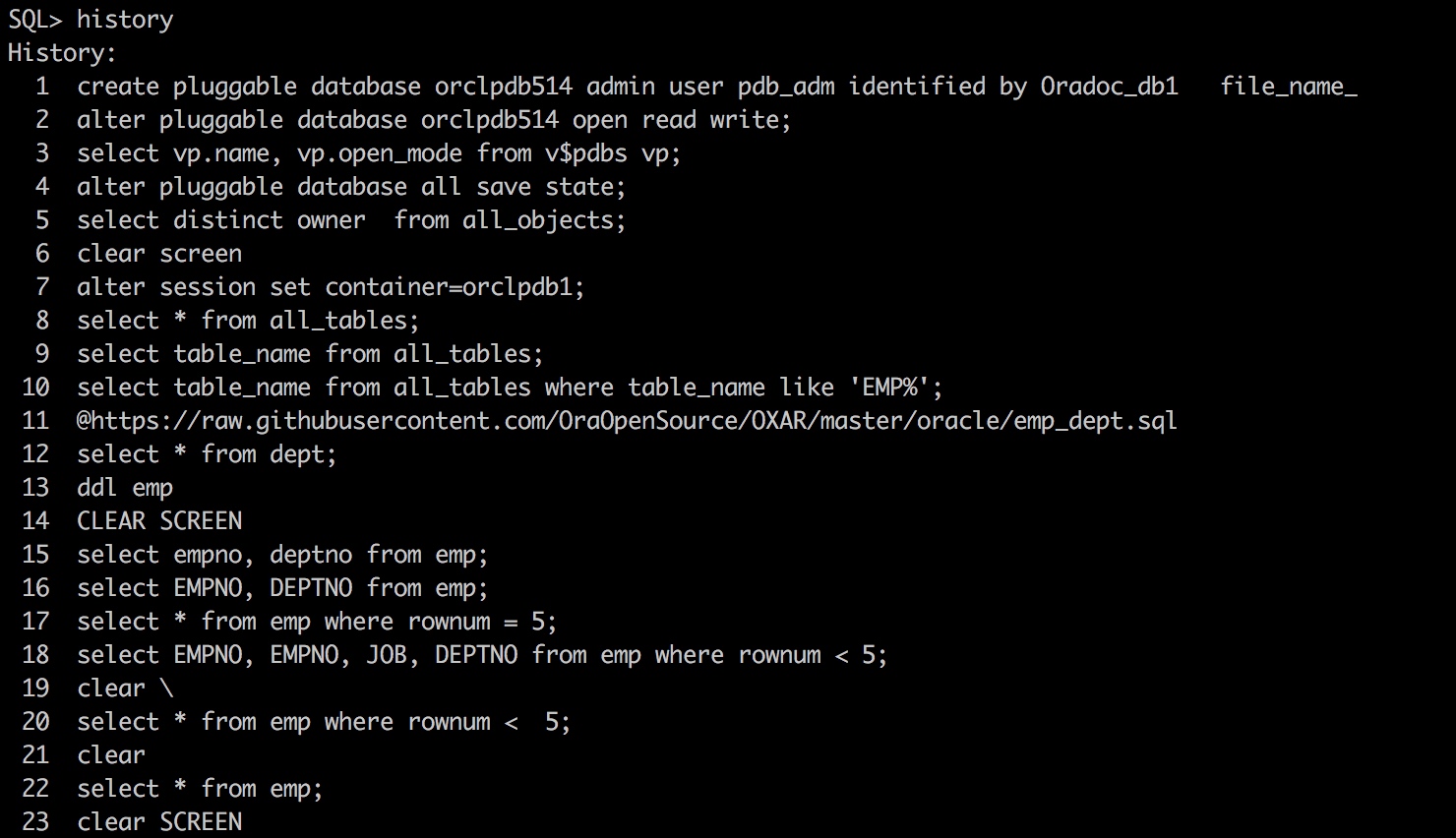
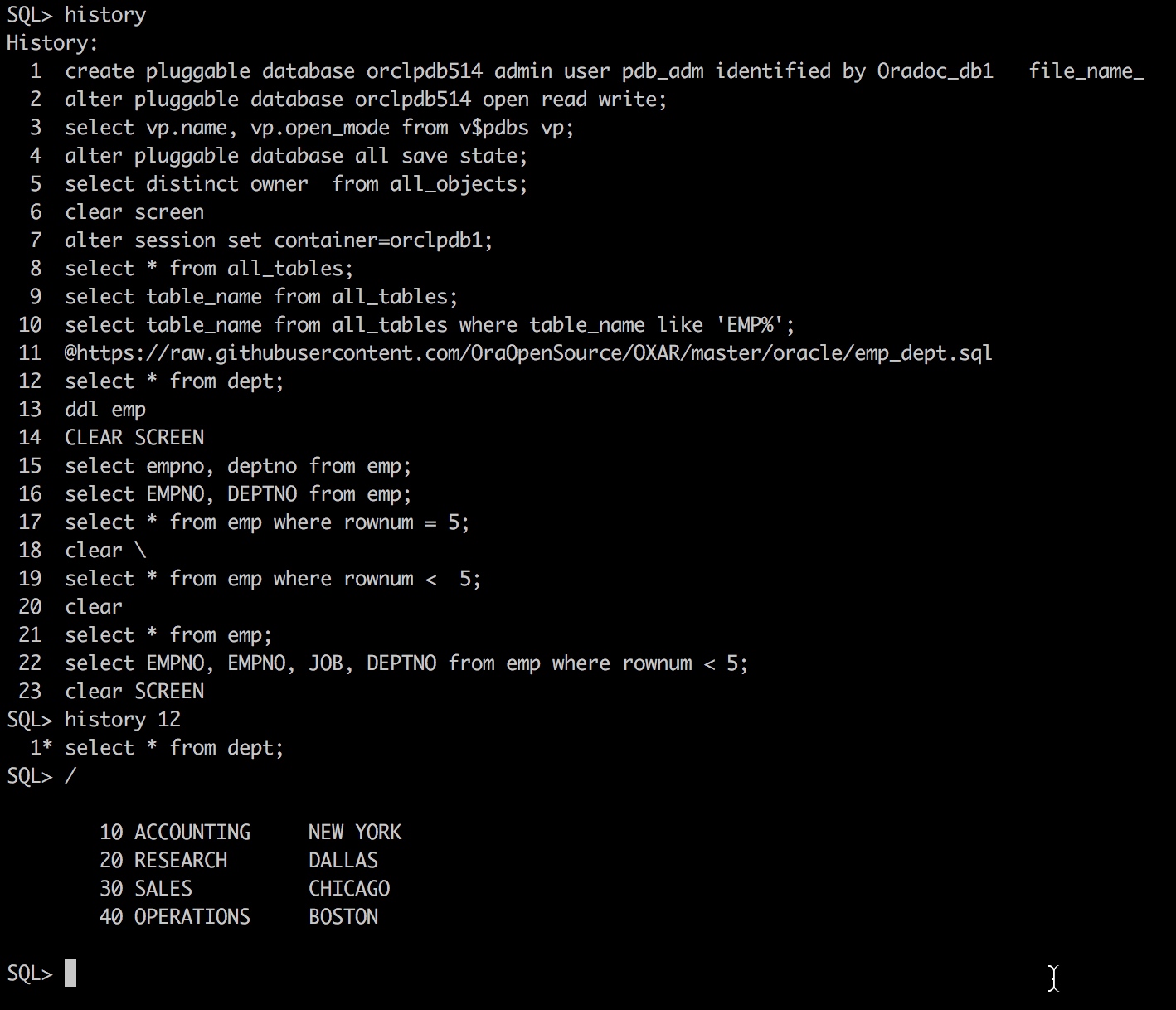
有两个简单例子,以说明 “exists”和“in”的效率问题 1) select * from T1 where exists(select 1 from T2 where T1.a=T2.a); T1数据量小而T2数据量非常大时,T1<<T2 时,1) 的查询效率高。
2) select * from T1 where T1.a in (select T2.a from T2); T1数据量非常大而T2数据量小时,T1>>T2 时,2) 的查询效率高。
exists 用法:
请注意 1)句中的有颜色字体的部分 ,理解其含义; 其中 “select 1 from T2 where T1.a=T2.a” 相当于一个关联表查询,相当于 “select 1 from T1,T2 where T1.a=T2.a” 但是,如果你只执行 1) 句括号里的语句,是会报语法错误的,这也是使用exists需要注意的地方。 “exists(xxx)”就表示括号里的语句能不能查出记录,它要查的记录是否存在。 因此“select 1”这里的 “1”其实是无关紧要的,换成“*”也没问题,它只在乎括号里的数据能不能查找出来,是否存在这样的记录,如果存在,这 1) 句的where 条件成立。
in 的用法:
继续引用上面的例子 2) select * from T1 where T1.a in (select T2.a from T2); 这里的“in”后面括号里的语句搜索出来的字段的内容一定要相对应,一般来说,T1和T2这两个表的a字段表达的意义应该是一样的,否则这样查没什么意义。 打个比方:T1,T2表都有一个字段,表示工单号,但是T1表示工单号的字段名叫“ticketid”,T2则为“id”,但是其表达的意义是一样的,而且数据格式也是一样的。这时,用 2)的写法就可以这样:
1 2 3
select * from T1 where T1.ticketid in (select T2.id from T2); select name from employee where name not in (select name from student); select name from employee where not exists (select name from student);
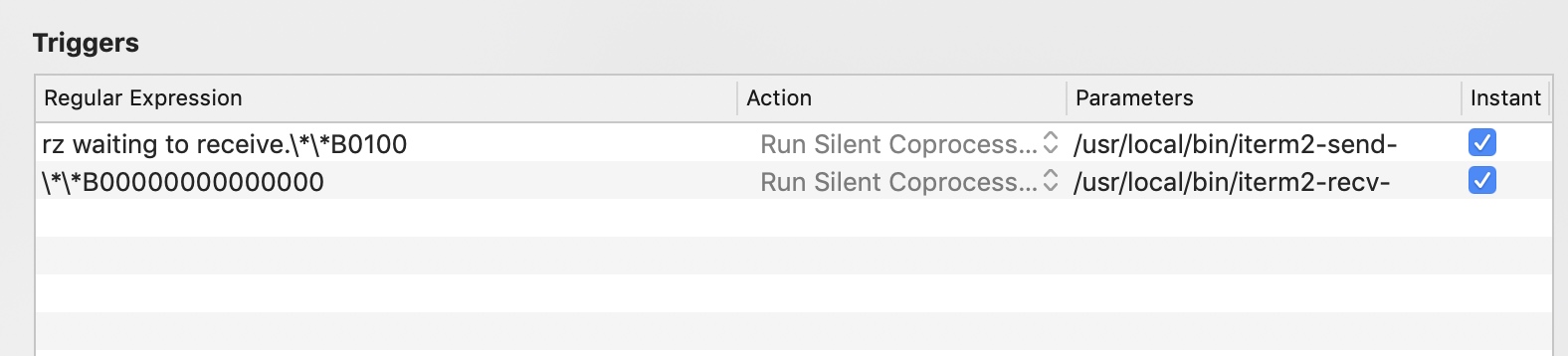
[oracle@oracle ~]$ vim /etc/systemd/system/oracle-rdbms.service # /etc/systemd/system/oracle-rdbms.service # Invoking Oracle scripts to start/shutdown Instances defined in /etc/oratab # and starts Listener
[Unit] Description=Oracle Database(s) and Listener Requires=network.target
[oracle@oracle ~]$ vim /etc/oratab # # This file is used by ORACLE utilities. It is created by root.sh # and updated by either Database Configuration Assistant while creating # a database or ASM Configuration Assistant while creating ASM instance. # A colon, ':', is used as the field terminator. A new line terminates # the entry. Lines beginning with a pound sign, '#', are comments. # # Entries are of the form: # $ORACLE_SID:$ORACLE_HOME:<N|Y>: # # The first and second fields are the system identifier and home # directory of the database respectively. The third field indicates # to the dbstart utility that the database should , "Y", or should not, # "N", be brought up at system boot time. # # Multiple entries with the same $ORACLE_SID are not allowed. # # orcl:/opt/oracle/app/product/12.2.0:Y
开启关闭em
开启em
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[oracle@oracle ~]$ rlwrap sqlplus / as sysdba
SQL*Plus: Release 12.2.0.1.0 Production on Sat Dec 15 09:09:47 2018
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to: Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SP2-0136: DEFINE requires an equal sign (=) SQL> exec DBMS_XDB_CONFIG.SETHTTPPORT(5500);
PL/SQL procedure successfully completed. SQL>
关闭em
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[oracle@oracle ~]$ rlwrap sqlplus / as sysdba
SQL*Plus: Release 12.2.0.1.0 Production on Sat Dec 15 09:11:28 2018
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to: Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SP2-0136: DEFINE requires an equal sign (=) SQL> exec DBMS_XDB_CONFIG.SETHTTPPORT(0);
defprint_max(x, y): '''Prints the maximum of two numbers.打印两个数值中的最大数。 The two values must be integers.这两个数都应该是整数''' # 如果可能,将其转换至整数类型 x = int(x) y = int(y)
if x > y: print(x, 'is maximum') else: print(y, 'is maximum')
print_max(3, 5) print(print_max.__doc__)
输出:
1 2 3 4 5
$ python function_docstring.py 5is maximum Prints the maximum of two numbers.
[root@lab8106 ceph]# parted /dev/sdd
GNU Parted 3.1
Using /dev/sdd
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: SEAGATE ST3300657SS (scsi)
Disk /dev/sdd: 300GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
(parted) mkpart primary 0 100%
Warning: The resulting partition is not properly aligned for best performance.
Ignore/Cancel?
Warning: The resulting partition is not properly aligned for best performance.